造假大师易富贤的浆糊统计学:“计划死亡”终于在他笔下变成现实
过去的几个星期,我跑到reddit的威斯康星大学小组去揭露易富贤造假,不出所料地,我收获了一大堆“shit”、“garbage”,还有不止一个人说我是“50-cent dogs”或“五毛”。(写到这里,先莞尔一下下 ^_^)。
不过,在成堆充满敌意的评论中,我也有了一个重大发现。
一位网名叫“Gibborim”、专业为“电子与计算机”(Electrical and Computer Engineering)的网民向我指出,易富贤所说的“每出生一万人,就有x人在y岁之前死亡”并非我理解的“0-y岁死亡率”,而且还非常仔细地给我解释了易富贤可能是怎么算出他那个证据的。当然,最后他还想让我相信易富贤的这种“专业”方法。
虽然他言辞激烈(如我一般^_^),但我在用自己那个小学算术不及格的愚钝大脑思考了几天后,终于认识到他的第一个说法是正确的:我确实误解了易富贤的说法。易富贤所说的“每出生一万人,就有x人在y岁之前死亡”,指的是这一万人在年满y岁之前的总死亡人数,也就是把他们在y+1年内的死亡人数相加的总数。
但这是否意味着易富贤和Gibborim的计算方法就是正确的呢?下面我就来作一个非专业的分析。如果有不正确的地方,欢迎各位指出来。
一、易富贤是怎样算出“每出生一万人,就有x人在y岁之前死亡”的
关于易富贤的算法,Gibborim作了非常详尽的分析,甚至还把他的计算结果做成一个图表,懂英文的网友可以参考他在我帖子后面的回复。
只是,对我这个小学算术不及格的脑瓜子来说,他这套算法太复杂,不过我还是理解了他和易富贤计算这个数据的大致思路。为了便于说明,我在这里把他们用来计算的那个表格的部分截图再贴出来(需要查看整个表格原文的请戳这里:http://www.stats.gov.cn/tjsj/ndsj/renkoupucha/2000pucha/html/t0604.htm):
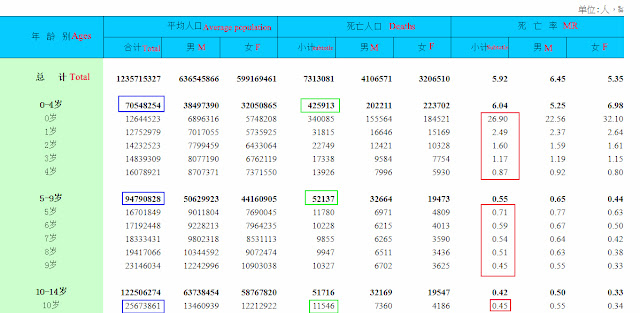
简单地说,要计算易富贤的那个“每出生一万人,就有x人在y岁之前死亡”,就需要知道这些人每年的死亡人数或死亡率。例如,如果要计算2000年出生的人总共有多少在10岁之前死亡,除了表格中已经提供的他们在0岁的死亡人数之外,我们还需要知道他们在1岁、2岁、3岁……直至10岁的每年死亡人数(一共11个数据),然后将这些人数相加,除以他们出生时的人数,再乘以万分之一万,就能得到易富贤说的那种数据了。
但是这个表格只提供了单个年龄在当年的死亡人数、总人数和死亡率,计算2000年出生的人总共有多少在10岁之前死亡所需的另外10个数据,在上述表格中是没有的。
中国有句话叫“巧妇难为无米之炊”,但这样庞大的数据缺失显然难不倒我们的造假大师易富贤。因为他直接就用表格中出生于其他年份的人的死亡率来推算相关年龄组在相应年龄的死亡人数了。
例如,从这个表格中,我们知道出生于2000年的人在0岁时的死亡率是26.9‰,那么他们到1岁、2岁、3岁……10岁……25岁……44岁时的死亡率是多少呢?这个表格没有提供,按照易富贤们的计算方法,他们实际上是用1999年生人在1岁时的死亡率计算2000年生人在2001年(即他们1岁时)的死亡人数,用1998年生人在2岁时的死亡率计算2000年生人在2002年(及他们2岁时)的死亡人数……以此类推。
(说白了,他这种算法儿的本质,就是此前此后的所有兲朝人,不管是出生于大饥荒时代、文革时代、改革开放时代还是21世纪,都得按照上述表格中的死亡率去死。反节育派向往的“计划死亡”终于在易富贤的“神笔”下变成现实。)
为了便于说明,我们先拿一个比较短的时间段来举例子,如果我们用n来表示某年生人的活产人数,用A、B、C……来表示上述表格中0-2岁的死亡率,那么该组在0岁的死亡人数是n*A,在1岁的死亡人数是(n-n*A)*B,在2岁的死亡人数是[n-n*A -(n-n*A)*B]*C
因此,按照易富贤们的算法,该组人在0-2岁的总死亡人数是:n*A+(n-n*A)*B+[n-n*A -(n-n*A)*B]*C=n*A+n*B-n*A*B+n*C-n*A*C-n*B*C+n*A*B*C=n*A+n*B+n*C-n*A*B-n*A*C-n*B*C+n*A*B*C
那么对于该组的人,每出生一万人,会有多少人在2岁之前死亡呢?其计算公式就是:
x=[(n*A+n*B+n*C-n*A*B-n*A*C-n*B*C+n*A*B*C)10000]/[n*10000]=(A+B+C-A*B-A*C-B*C+A*B*C)*10000/10000
也就是x=(A+B+C+……-A*B-A*C-B*C-……+A*B*C*……) *10000/10000
(很久没做数学题,写到这里已经两眼发花或昏花*_*)
由于表格中的死亡率是千分比,例如0岁死亡率是26.9‰(即0.0269),1岁死亡率为2.49‰(即0.00249),2岁死亡率为1.60‰(即0.0016)因此
Gibborim还不惮麻烦地挨个算出原表格中每个年龄总共有多少人在25岁之前死亡,从这个公式看,他/她完全是多此一举。
二、易富贤的算法是否可行?
通过上述表格中的数据,用易富贤的这种方法能否计算“每出生一万人有多少人在y岁之前死亡”,并进而算出失独家庭的数量呢?
笔者认为,他的方法并非完全不可行,但必须满足3个非常苛刻的条件:
1. 该国必须数十年处于发展停滞状态;
2. 该国数十年都没有影响人口死亡率的大型天灾人祸
3. 该国必须处于绝对平均主义状态。
条件1中所说的“发展停滞”,意思是既不发展也不后退,因为科技进步和经济发展都会降低人口死亡率,尤其是婴儿死亡率(即0岁死亡率),反之则可能提高这些死亡率;而条件2所说的大规模天灾人祸如战争、疫病之类也会提高人口死亡率,例如欧洲中世纪的黑死病和两次世界大战,都造成大量人口死亡,相应也就推高了相关国家和地区在那些时代的死亡率。
至于条件3中所说的绝对平均主义状态,则是为了消除不同社会阶层因经济条件不同造成的死亡率差异,否则像易富贤那样,把全国性的人口数据用来计算作为群体之一的独生子女的死亡人数,就会非常不靠谱。
我挠着脑瓜子想了半天,觉得我们根本无法在地球上找到完全符合上诉3个条件的国家,甚至连接近这3个条件的国家都很难找到,兲朝就更是概莫能外了。
不信的话就请去看看维基百科里的“世界婴儿死亡率列表”:在过去的五六十年里,全球所有国家的该项数据都有大大改观,排在第一位的新加坡,从1950年代初的60.69‰降低到21世纪初的1.92‰;而排在末尾的阿富汗,也从275.03‰降低到135.95‰。这就是科技进步和经济发展能够降低人口死亡率的证据。
blablabla这么多,我其实就想说明一件事:在现实社会中,易富贤的这套荒诞计算方法几乎是不可行的。
三、易富贤到底错在哪里?
如果对统计学稍微有点了解(例如我这个水平),那么我们就不难看出,在利用前述表格中的数据作分析和计算时,易富贤犯了两个非常明显的错误:
错误一,是用一个整体中某个群体的数据推算其他群体的数据。打个比方说,我们是不能根据某年上海的人均GDP推算该年度或其他年度甘肃的GDP总量滴(即用该年上海人均GDP乘以相应年份的甘肃人口总数)。
错误二,是用整体的数据推算其中某个群体的数据。打个比方说,我们是不能用某年全国的人均GDP推算甘肃或上海的GDP总量滴(即用该年全国人均GDP乘以同年的甘肃或上海人口总数)。
具体到这里来说就是,当易富贤把2000年、1999年、1998年、1997年……1975年……1956年生人分别处于0岁、1岁、2岁、3岁……25岁……44岁时的死亡率,当作其中一个或所有小组(其实计算其中任何小组都可以得出他算的数据,因为我们从前面的公式已经可以看出来,他所谓的“每出生一万人就有多少人在多少岁死亡”,就跟把相应年龄组的死亡率相加差不多)在相应年龄的死亡率时,他犯了第一个错误。
当易富贤用这个本身就是用错误方法算出的死亡数据来计算失独家庭的数量时,他犯了第二个错误。因为,正如我在《反节育派弥天大谎之一:“失独家庭上千万”》中所言,中国严格实行一胎化的地区主要是城市,而中国的城乡差距一直很大,相应地,也就造成城乡人口死亡率差距。所以,即使他的第一个数据是准确的,用这个全国性的平均数据来计算作为群体之一的独生子女的死亡数量,也会有很大的误差。更何况,他还是用历史数据推算未来的情况,这就更是多重不靠谱了。
这也是每次统计局发布全国人均收入时,好多网友都大呼自己的收入“被平均”了的原因。因为我们本来就不能用那个人均收入用来计算单个个体(或部分群体)的收入。我们能做的,只能是拿自己的实际收入跟全国人均收入作对比,看看自己的经济状况在全国大致处于哪个阶层。
那么,有没有比较可靠的办法从有限的数据中推算“每出生一万人,就有多少人在多少岁之前死亡”呢?答案是:有的。
例如,如果我们能从其他地方找到比较可靠的数据说明1990年、1975年和1956年的出生人口数量,那么再结合上述表格,就很容易算出那个“每出生一万人就有多少人在10岁、25岁和44岁之前死亡”了。
只是,在这句话之前,请一定要加上相应的年份,决不能像易富贤那样,把由此算出的数据概而括之、想当然地适用于所有年代(这也是他犯的第三个错误),更不能用它们去推算独生子女死亡人数。顶多,也只能根据这些数据,来非常非常非常粗略地比较一下前面两个年份(第3个年份不算,因为那会儿还没实行计生)出生的独生子女可能的死亡趋势是高还是低。
分析到这里,我们不难得出结论:易富贤在计算“失独家庭上千万”时至少犯了3个错误,从本质上说,它们都是反统计学的,也是反科学的。说得难听一点,他这些可笑的方法不过是一团胡诌,简直就是“浆糊统计学”,这也是他的“数据造假学”的方法论基础。只是,凭借他作为“美国威斯康星大学高级科学家”的地位,他这类不伦不类的数据颇能糊弄一般受众,包括众多记者,包括一些国际著名媒体的记者。
四、如何解读媒体报道中的数据和结论?
易富贤的“失独家庭上千万”之所以流传多年且流毒全球,固然主要是一些群体故意炒作反节育反计生话题造成的,但也跟全球媒体记者的集体缺乏专业精神有关。
审视各家媒体有关易富贤这个数据(以及他的一些其他“研究成果”)的报道,我们都会发现,从《环球时报》到《纽约时报》,有相当多的文章几乎都只摆出了易富贤的观点和/或与易富贤类似的观点,很少有记者去采访那些与他观点相异甚至相反的专业人士。因此,自然也就不会有专业人士去检验易富贤的数据和“研究成果”了。
不过,在我开始揭露易富贤造假之后,有少数媒体在报道他的“研究成果”时开始注意改变这种具有明显倾向性、只有单一观点的做法。例如《纽约时报》那篇《印度人口已经超越中国?》,不仅在标题中加上一个问号,而且在正文中阐述了易富贤的观点后,还加上了其他中国人口学家甚至新德里一位研究印度人口问题的教授的不同意见。这样一来,报道就显得更公允了。幸好媒体的专业精神还没有彻底死绝。
所以,当我们阅读各种媒体甚至自媒体的各种新闻和消息时,一定要对那些观点和立场单一的报道保持警惕(这种报道是兲朝“新闻”的主流),因为这样的报道就算不是彻头彻尾的谎言,至少也是有失偏颇的。
如果有某个号称专家的家伙,自称根据什么权威统计数据计算出什么结果(特别是那些看起来非常庞大的数字),却对自己的推算过程讳莫如深,甚至也对统计数据的来源讳莫如深,而文章中同样只列出他或她及其支持者的观点,那就更要保持警惕了。因为这就是易富贤之流一贯的做法。
写到这里,我还想调侃一下自己在墙内外的遭遇:当我试图在墙内说真话时,兲朝网民(以五毛水军为主)骂我是美分党;当我试图在墙外说真话时,一些西方网民骂我是五毛狗。看起来,不论是在墙内还是墙外,说真话的人都是不受欢迎的,因为真相往往刺眼。
再次感谢reddit网友Gibborim指出我的理解错误并向我详细解释易富贤的计算方法。我们之间的互动证明了达赖喇嘛尊者的那句名言:“从不同角度看问题,视野会更加开阔。” 为此,我可以原谅你骂我是五毛狗。(好吧,我承认自己其实根本就不在乎你对我的看法。 ^_^)
最后,模仿泡泡网的风格,祝各位做一个明智的信息消费者。不管谎言的雾霾多么黏稠,我们都要努力探索真相。
也祝大家情人节快乐,春节快乐!
------------
延伸阅读:
《谁给了易富贤造假的贼胆》
《害死马茸茸的幕后真凶是谁?》
《RFA和“安邦”咨询已沦为共匪私生子?》
《转:计划生育最大的罪过之一,是给了易富贤这种草包一个哗众取宠名利双收的机会》
《要多少人间悲剧,才能证明“多子多福”的荒谬?》
《“五四”百年:抄近路抄出来的冤枉路》
不过,在成堆充满敌意的评论中,我也有了一个重大发现。
一位网名叫“Gibborim”、专业为“电子与计算机”(Electrical and Computer Engineering)的网民向我指出,易富贤所说的“每出生一万人,就有x人在y岁之前死亡”并非我理解的“0-y岁死亡率”,而且还非常仔细地给我解释了易富贤可能是怎么算出他那个证据的。当然,最后他还想让我相信易富贤的这种“专业”方法。
虽然他言辞激烈(如我一般^_^),但我在用自己那个小学算术不及格的愚钝大脑思考了几天后,终于认识到他的第一个说法是正确的:我确实误解了易富贤的说法。易富贤所说的“每出生一万人,就有x人在y岁之前死亡”,指的是这一万人在年满y岁之前的总死亡人数,也就是把他们在y+1年内的死亡人数相加的总数。
但这是否意味着易富贤和Gibborim的计算方法就是正确的呢?下面我就来作一个非专业的分析。如果有不正确的地方,欢迎各位指出来。
一、易富贤是怎样算出“每出生一万人,就有x人在y岁之前死亡”的
关于易富贤的算法,Gibborim作了非常详尽的分析,甚至还把他的计算结果做成一个图表,懂英文的网友可以参考他在我帖子后面的回复。
只是,对我这个小学算术不及格的脑瓜子来说,他这套算法太复杂,不过我还是理解了他和易富贤计算这个数据的大致思路。为了便于说明,我在这里把他们用来计算的那个表格的部分截图再贴出来(需要查看整个表格原文的请戳这里:http://www.stats.gov.cn/tjsj/ndsj/renkoupucha/2000pucha/html/t0604.htm):
简单地说,要计算易富贤的那个“每出生一万人,就有x人在y岁之前死亡”,就需要知道这些人每年的死亡人数或死亡率。例如,如果要计算2000年出生的人总共有多少在10岁之前死亡,除了表格中已经提供的他们在0岁的死亡人数之外,我们还需要知道他们在1岁、2岁、3岁……直至10岁的每年死亡人数(一共11个数据),然后将这些人数相加,除以他们出生时的人数,再乘以万分之一万,就能得到易富贤说的那种数据了。
但是这个表格只提供了单个年龄在当年的死亡人数、总人数和死亡率,计算2000年出生的人总共有多少在10岁之前死亡所需的另外10个数据,在上述表格中是没有的。
中国有句话叫“巧妇难为无米之炊”,但这样庞大的数据缺失显然难不倒我们的造假大师易富贤。因为他直接就用表格中出生于其他年份的人的死亡率来推算相关年龄组在相应年龄的死亡人数了。
例如,从这个表格中,我们知道出生于2000年的人在0岁时的死亡率是26.9‰,那么他们到1岁、2岁、3岁……10岁……25岁……44岁时的死亡率是多少呢?这个表格没有提供,按照易富贤们的计算方法,他们实际上是用1999年生人在1岁时的死亡率计算2000年生人在2001年(即他们1岁时)的死亡人数,用1998年生人在2岁时的死亡率计算2000年生人在2002年(及他们2岁时)的死亡人数……以此类推。
(说白了,他这种算法儿的本质,就是此前此后的所有兲朝人,不管是出生于大饥荒时代、文革时代、改革开放时代还是21世纪,都得按照上述表格中的死亡率去死。反节育派向往的“计划死亡”终于在易富贤的“神笔”下变成现实。)
为了便于说明,我们先拿一个比较短的时间段来举例子,如果我们用n来表示某年生人的活产人数,用A、B、C……来表示上述表格中0-2岁的死亡率,那么该组在0岁的死亡人数是n*A,在1岁的死亡人数是(n-n*A)*B,在2岁的死亡人数是[n-n*A -(n-n*A)*B]*C
因此,按照易富贤们的算法,该组人在0-2岁的总死亡人数是:n*A+(n-n*A)*B+[n-n*A -(n-n*A)*B]*C=n*A+n*B-n*A*B+n*C-n*A*C-n*B*C+n*A*B*C=n*A+n*B+n*C-n*A*B-n*A*C-n*B*C+n*A*B*C
那么对于该组的人,每出生一万人,会有多少人在2岁之前死亡呢?其计算公式就是:
x=[(n*A+n*B+n*C-n*A*B-n*A*C-n*B*C+n*A*B*C)10000]/[n*10000]=(A+B+C-A*B-A*C-B*C+A*B*C)*10000/10000
也就是x=(A+B+C+……-A*B-A*C-B*C-……+A*B*C*……) *10000/10000
(很久没做数学题,写到这里已经两眼发花或昏花*_*)
由于表格中的死亡率是千分比,例如0岁死亡率是26.9‰(即0.0269),1岁死亡率为2.49‰(即0.00249),2岁死亡率为1.60‰(即0.0016)因此
A*B=0.000066981≈0.00007,
A*C=0.00004304 ≈0.00004
B*C=0.00003984 ≈0.000005
A*B*C=0.0000001072
相乘的死亡率个数越多,得出的数字就越小,除了那个0.00007和0.00004之外,其余的几乎可以忽略不计。难怪易富贤算出的那些数字就跟直接把各年龄的死亡率相加差不多!A*C=0.00004304 ≈0.00004
B*C=0.00003984 ≈0.000005
A*B*C=0.0000001072
Gibborim还不惮麻烦地挨个算出原表格中每个年龄总共有多少人在25岁之前死亡,从这个公式看,他/她完全是多此一举。
二、易富贤的算法是否可行?
通过上述表格中的数据,用易富贤的这种方法能否计算“每出生一万人有多少人在y岁之前死亡”,并进而算出失独家庭的数量呢?
笔者认为,他的方法并非完全不可行,但必须满足3个非常苛刻的条件:
1. 该国必须数十年处于发展停滞状态;
2. 该国数十年都没有影响人口死亡率的大型天灾人祸
3. 该国必须处于绝对平均主义状态。
条件1中所说的“发展停滞”,意思是既不发展也不后退,因为科技进步和经济发展都会降低人口死亡率,尤其是婴儿死亡率(即0岁死亡率),反之则可能提高这些死亡率;而条件2所说的大规模天灾人祸如战争、疫病之类也会提高人口死亡率,例如欧洲中世纪的黑死病和两次世界大战,都造成大量人口死亡,相应也就推高了相关国家和地区在那些时代的死亡率。
至于条件3中所说的绝对平均主义状态,则是为了消除不同社会阶层因经济条件不同造成的死亡率差异,否则像易富贤那样,把全国性的人口数据用来计算作为群体之一的独生子女的死亡人数,就会非常不靠谱。
我挠着脑瓜子想了半天,觉得我们根本无法在地球上找到完全符合上诉3个条件的国家,甚至连接近这3个条件的国家都很难找到,兲朝就更是概莫能外了。
不信的话就请去看看维基百科里的“世界婴儿死亡率列表”:在过去的五六十年里,全球所有国家的该项数据都有大大改观,排在第一位的新加坡,从1950年代初的60.69‰降低到21世纪初的1.92‰;而排在末尾的阿富汗,也从275.03‰降低到135.95‰。这就是科技进步和经济发展能够降低人口死亡率的证据。
blablabla这么多,我其实就想说明一件事:在现实社会中,易富贤的这套荒诞计算方法几乎是不可行的。
三、易富贤到底错在哪里?
如果对统计学稍微有点了解(例如我这个水平),那么我们就不难看出,在利用前述表格中的数据作分析和计算时,易富贤犯了两个非常明显的错误:
错误一,是用一个整体中某个群体的数据推算其他群体的数据。打个比方说,我们是不能根据某年上海的人均GDP推算该年度或其他年度甘肃的GDP总量滴(即用该年上海人均GDP乘以相应年份的甘肃人口总数)。
错误二,是用整体的数据推算其中某个群体的数据。打个比方说,我们是不能用某年全国的人均GDP推算甘肃或上海的GDP总量滴(即用该年全国人均GDP乘以同年的甘肃或上海人口总数)。
具体到这里来说就是,当易富贤把2000年、1999年、1998年、1997年……1975年……1956年生人分别处于0岁、1岁、2岁、3岁……25岁……44岁时的死亡率,当作其中一个或所有小组(其实计算其中任何小组都可以得出他算的数据,因为我们从前面的公式已经可以看出来,他所谓的“每出生一万人就有多少人在多少岁死亡”,就跟把相应年龄组的死亡率相加差不多)在相应年龄的死亡率时,他犯了第一个错误。
当易富贤用这个本身就是用错误方法算出的死亡数据来计算失独家庭的数量时,他犯了第二个错误。因为,正如我在《反节育派弥天大谎之一:“失独家庭上千万”》中所言,中国严格实行一胎化的地区主要是城市,而中国的城乡差距一直很大,相应地,也就造成城乡人口死亡率差距。所以,即使他的第一个数据是准确的,用这个全国性的平均数据来计算作为群体之一的独生子女的死亡数量,也会有很大的误差。更何况,他还是用历史数据推算未来的情况,这就更是多重不靠谱了。
这也是每次统计局发布全国人均收入时,好多网友都大呼自己的收入“被平均”了的原因。因为我们本来就不能用那个人均收入用来计算单个个体(或部分群体)的收入。我们能做的,只能是拿自己的实际收入跟全国人均收入作对比,看看自己的经济状况在全国大致处于哪个阶层。
那么,有没有比较可靠的办法从有限的数据中推算“每出生一万人,就有多少人在多少岁之前死亡”呢?答案是:有的。
例如,如果我们能从其他地方找到比较可靠的数据说明1990年、1975年和1956年的出生人口数量,那么再结合上述表格,就很容易算出那个“每出生一万人就有多少人在10岁、25岁和44岁之前死亡”了。
只是,在这句话之前,请一定要加上相应的年份,决不能像易富贤那样,把由此算出的数据概而括之、想当然地适用于所有年代(这也是他犯的第三个错误),更不能用它们去推算独生子女死亡人数。顶多,也只能根据这些数据,来非常非常非常粗略地比较一下前面两个年份(第3个年份不算,因为那会儿还没实行计生)出生的独生子女可能的死亡趋势是高还是低。
分析到这里,我们不难得出结论:易富贤在计算“失独家庭上千万”时至少犯了3个错误,从本质上说,它们都是反统计学的,也是反科学的。说得难听一点,他这些可笑的方法不过是一团胡诌,简直就是“浆糊统计学”,这也是他的“数据造假学”的方法论基础。只是,凭借他作为“美国威斯康星大学高级科学家”的地位,他这类不伦不类的数据颇能糊弄一般受众,包括众多记者,包括一些国际著名媒体的记者。
四、如何解读媒体报道中的数据和结论?
易富贤的“失独家庭上千万”之所以流传多年且流毒全球,固然主要是一些群体故意炒作反节育反计生话题造成的,但也跟全球媒体记者的集体缺乏专业精神有关。
审视各家媒体有关易富贤这个数据(以及他的一些其他“研究成果”)的报道,我们都会发现,从《环球时报》到《纽约时报》,有相当多的文章几乎都只摆出了易富贤的观点和/或与易富贤类似的观点,很少有记者去采访那些与他观点相异甚至相反的专业人士。因此,自然也就不会有专业人士去检验易富贤的数据和“研究成果”了。
不过,在我开始揭露易富贤造假之后,有少数媒体在报道他的“研究成果”时开始注意改变这种具有明显倾向性、只有单一观点的做法。例如《纽约时报》那篇《印度人口已经超越中国?》,不仅在标题中加上一个问号,而且在正文中阐述了易富贤的观点后,还加上了其他中国人口学家甚至新德里一位研究印度人口问题的教授的不同意见。这样一来,报道就显得更公允了。幸好媒体的专业精神还没有彻底死绝。
所以,当我们阅读各种媒体甚至自媒体的各种新闻和消息时,一定要对那些观点和立场单一的报道保持警惕(这种报道是兲朝“新闻”的主流),因为这样的报道就算不是彻头彻尾的谎言,至少也是有失偏颇的。
如果有某个号称专家的家伙,自称根据什么权威统计数据计算出什么结果(特别是那些看起来非常庞大的数字),却对自己的推算过程讳莫如深,甚至也对统计数据的来源讳莫如深,而文章中同样只列出他或她及其支持者的观点,那就更要保持警惕了。因为这就是易富贤之流一贯的做法。
写到这里,我还想调侃一下自己在墙内外的遭遇:当我试图在墙内说真话时,兲朝网民(以五毛水军为主)骂我是美分党;当我试图在墙外说真话时,一些西方网民骂我是五毛狗。看起来,不论是在墙内还是墙外,说真话的人都是不受欢迎的,因为真相往往刺眼。
再次感谢reddit网友Gibborim指出我的理解错误并向我详细解释易富贤的计算方法。我们之间的互动证明了达赖喇嘛尊者的那句名言:“从不同角度看问题,视野会更加开阔。” 为此,我可以原谅你骂我是五毛狗。(好吧,我承认自己其实根本就不在乎你对我的看法。 ^_^)
最后,模仿泡泡网的风格,祝各位做一个明智的信息消费者。不管谎言的雾霾多么黏稠,我们都要努力探索真相。
也祝大家情人节快乐,春节快乐!
------------
延伸阅读:
《谁给了易富贤造假的贼胆》
《害死马茸茸的幕后真凶是谁?》
《RFA和“安邦”咨询已沦为共匪私生子?》
《转:计划生育最大的罪过之一,是给了易富贤这种草包一个哗众取宠名利双收的机会》
《要多少人间悲剧,才能证明“多子多福”的荒谬?》
《“五四”百年:抄近路抄出来的冤枉路》

留言
張貼留言